Paper close reading: "Why Language Models Hallucinate"
People often talk about paper reading as a skill, but there aren’t that many examples of people walking through how they do it. Part of this is a problem of supply: it’s expensive to document one’s thought process for any significant length of time, and there’s the additional cost of probably looking quite foolish when doing so. Part of this is simply a question of demand: far more people will read a short paragraph or tweet thread summarizing a paper and offering some pithy comments, than a thousand-word post of someone’s train of thought as they look through a paper. Thankfully, I’m willing to risk looking a bit foolish, and I’m pretty unresponsive to demand at this present moment, so I’ll try and write down my thought processes as I read through as much of a a paper I can in 1-2 hours. Standard disclaimers apply: this is unlikely to be fully faithful for numerous reasons, including the fact that I read and think substantially faster than I can type or talk. [1] Specifically, I tried to do this for a paper from last year: “Why Language Models Hallucinate” , by Kalai et al at OpenAI. [2] Due to time constraints, I only managed to make it through the abstract and introduction before running out of time. Oops. Maybe I’ll try recording myself talking through another close reading later. The Abstract The abstract of the paper starts: Like students facing hard exam questions, large language models sometimes guess when uncertain,
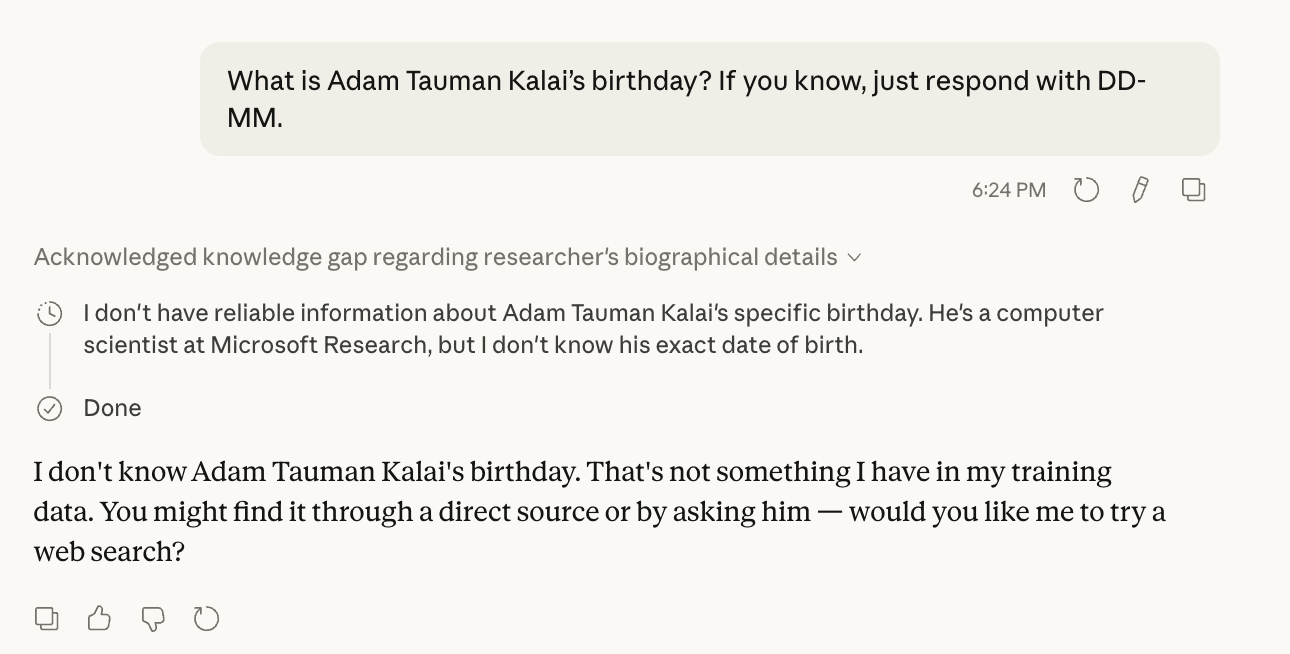
People often talk about paper reading as a skill, but there aren’t that many examples of people walking through how they do it. Part of this is a problem of supply: it’s expensive to document one’s thought process for any significant length of time, and there’s the additional cost of probably looking quite foolish when doing so. Part of this is simply a question of demand: far more people will read a short paragraph or tweet thread summarizing a paper and offering some pithy comments, than a thousand-word post of someone’s train of thought as they look through a paper. Thankfully, I’m willing to risk looking a bit foolish, and I’m pretty unresponsive to demand at this present moment, so I’ll try and write down my thought processes as I read through as much of a paper I can in 1-2 hours. Standard disclaimers apply: this is unlikely to be fully faithful for numerous reasons, including the fact that I read and think substantially faster than I can type or talk. [1] Specifically, I tried to do this for a paper from last year: “Why Language Models Hallucinate” , by Kalai et al at OpenAI. [2] Due to time constraints, I only managed to make it through the abstract and introduction before running out of time. Oops. Maybe I’ll try recording myself talking through another close reading later.
The Abstract
The abstract of the paper starts: "Like students facing hard exam questions, large language models sometimes guess when uncertain, producing plausible yet incorrect statements instead of admitting uncertainty. Such 'hallucinations' persist even in state-of-the-art systems and undermine trust." To me, this reads like pretty standard boilerplate, though it’s worth noting that this is a specific definition of “hallucination” that doesn’t capture everything we might call a hallucination. Off the top of my head, I’ve heard people refer to failures in logical deduction as “hallucinations.” For example, many would consider this example a hallucination:
User: What are the roots of 2?
AI: The square root of 2 is approximately 1.414.
This response is technically correct, but it doesn’t address the question of roots in the context of polynomial equations. The AI might have inferred this from the word "roots" and its common association with square roots, but it didn’t consider the broader context of the question. This kind of failure, where the model provides an answer that’s technically correct but not relevant to the question asked, could be seen as a form of hallucination.
The Introduction
The introduction sets the stage by discussing the limitations of large language models (LLMs) and their tendency to produce incorrect or unverified information. The authors argue that this behavior, or hallucination, is a significant issue that undermines the reliability and trust in these models. They mention that even state-of-the-art systems, which are highly advanced and trained on vast amounts of data, still exhibit hallucinations.
The authors provide a brief overview of related work, mentioning previous studies that have explored the problem of hallucinations in LLMs. They note that while some research has focused on detecting hallucinations, there is a lack of understanding about the underlying causes and mechanisms that lead to this behavior. The paper aims to address this gap by investigating the factors that contribute to hallucinations in LLMs.
Key Questions Addressed
The introduction outlines several key questions that the paper seeks to answer:
1. What are the factors that lead to hallucinations in LLMs?
2. How can we better understand and predict when a model will hallucinate?
3. What are the implications of hallucinations for the use and deployment of LLMs in real-world applications?
The authors propose that by understanding these factors, we can develop strategies to mitigate hallucinations and improve the reliability of LLMs.
Implications and Future Work
The paper concludes its introduction by discussing the broader implications of its findings. The authors emphasize that addressing hallucinations is crucial for building trust in LLMs and ensuring their safe and effective use in various applications, such as healthcare, education, and customer service. They also suggest that further research is needed to develop more robust methods for detecting and preventing hallucinations.
In summary, the paper "Why Language Models Hallucinate" by Kalai et al at OpenAI aims to shed light on the issue of hallucinations in large language models. By examining the factors that contribute to this behavior, the authors hope to pave the way for improved models and more reliable applications of AI. While I was only able to skim through the abstract and introduction due to time constraints, the paper seems to address an important and timely topic in the field of natural language processing.
[1] Specifically, I tried to do this for a paper from last year: “Why Language Models Hallucinate” , by Kalai et al at OpenAI.
[2] Due to time constraints, I only managed to make it through the abstract and introduction before running out of time. Oops. Maybe I’ll try recording myself talking through another close reading later.









